
Artificial intelligence has been the subject of much hype in recent years. The reason for this is the progress made in the field of machine learning. This article gives an overview of the topic and is suitable for beginners and advanced users.
Types of Machine Learning
Machine learning is a subset of artificial intelligence that focuses on developing algorithms and statistical models that allow computer systems to perform tasks without explicit instructions. Instead, these systems learn patterns from data and use that knowledge to make predictions or decisions. These learning approaches fall into five main categories, each with its own way of processing and learning from data:
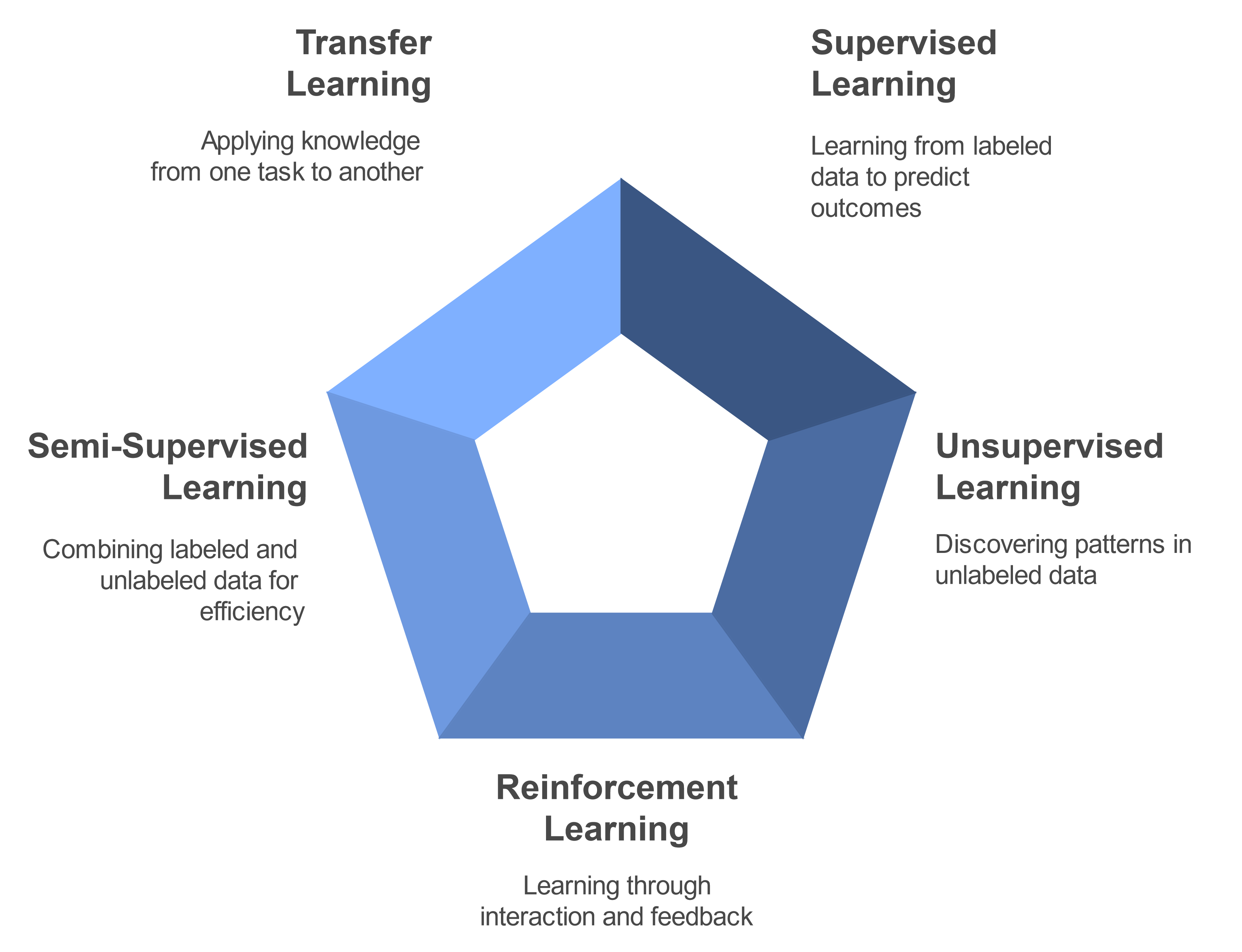
Supervised Learning
In supervised learning, algorithms are trained on labeled data, learning to map input data to known output labels. This type of learning is analogous to learning with a teacher, where the algorithm is shown correct answers and learns to replicate them.
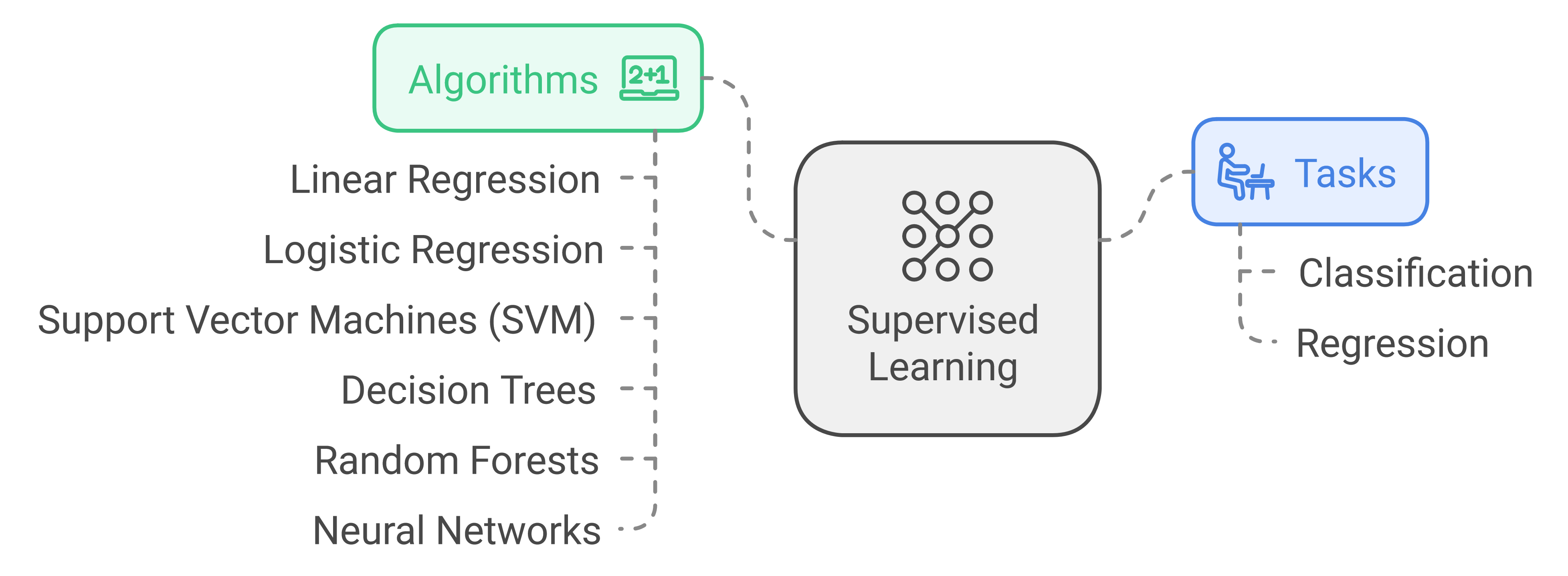
Common tasks:
Classification: Categorizing data into predefined classes (e.g., spam detection in emails)
Regression: Predicting continuous values (e.g., house price prediction)
Popular Algorithms:
Linear Regression: A regression algorithm that models the relationship between input and output as a straight line.
Logistic Regression: A classification algorithm that predicts binary outcomes.
Support Vector Machines (SVM): A classification algorithm that finds the best boundary to separate data points into classes.
Decision Trees: A tree-based model that splits data based on features to make predictions.
Random Forests: An ensemble learning method that combines multiple decision trees. It improves prediction accuracy by averaging the outputs of individual trees.
Neural Networks: A set of algorithms inspired by the human brain, capable of finding complex patterns.
Unsupervised Learning
Unsupervised learning algorithms work with unlabeled data, attempting to find hidden patterns or structures. This type of learning is like learning without a teacher, where the algorithm must discover patterns on its own.
Key techniques:
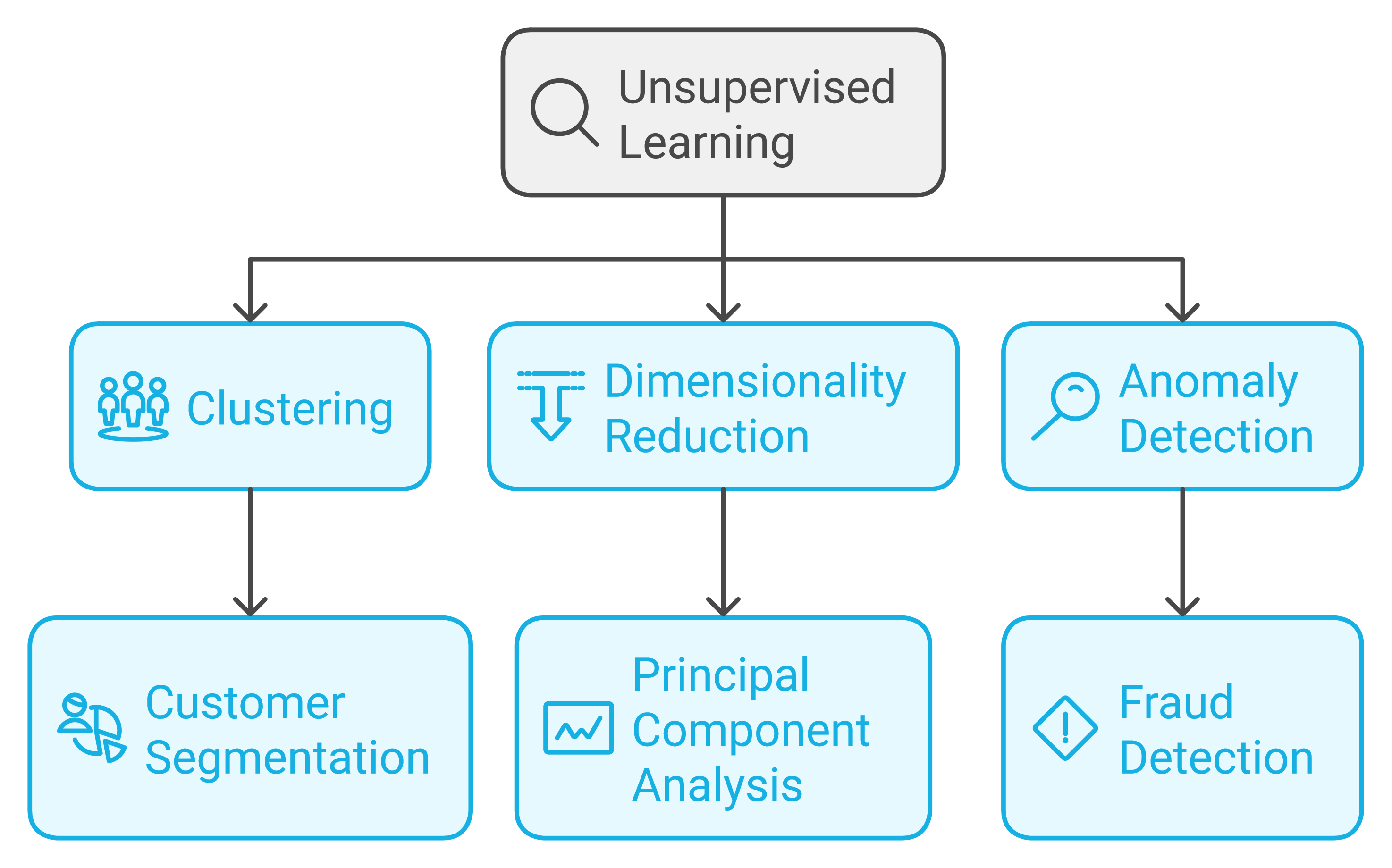
Clustering: Grouping similar data points together (e.g., customer segmentation)
Dimensionality reduction: Reducing the number of features in a dataset while preserving important information (e.g., Principal Component Analysis)
Anomaly detection: Identifying unusual patterns in data (e.g., fraud detection)
Popular algorithms:
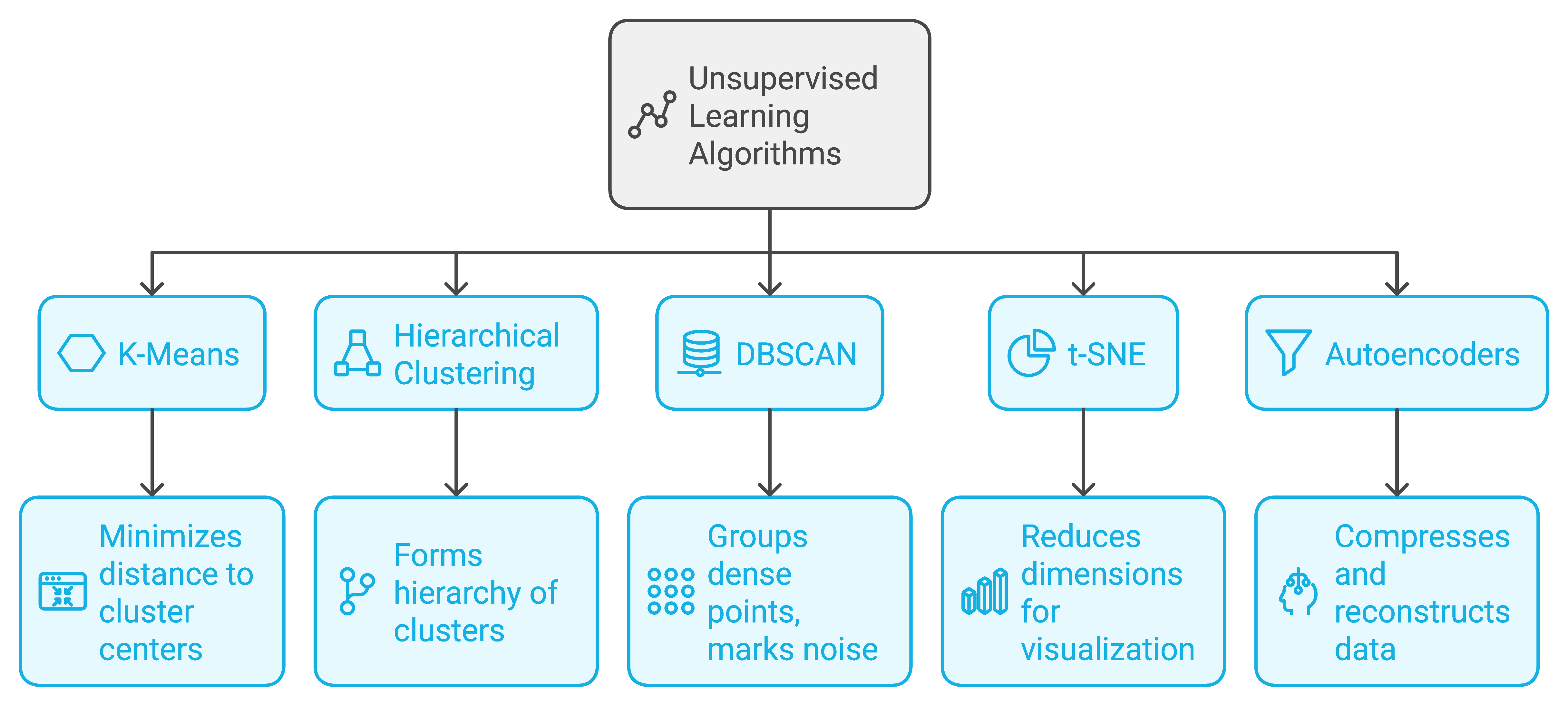
K-Means: A clustering algorithm that divides data into a set number of clusters. It does this by minimizing the distance between each data point and its cluster’s center.
Hierarchical Clustering: An algorithm that creates a hierarchy of clusters by iteratively merging or splitting data points based on their similarity, forming a tree-like structure.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise): A density-based clustering method that groups points close together. Points in sparse regions are marked as noise.
t-SNE (t-Distributed Stochastic Neighbor Embedding): A technique for reducing data dimensions, often used in visualization.
Autoencoders: A type of neural network used for compressing and reconstructing data.
Reinforcement Learning
This type of learning involves an agent interacting with an environment, learning to make decisions by receiving rewards or penalties. It's analogous to learning through trial and error.
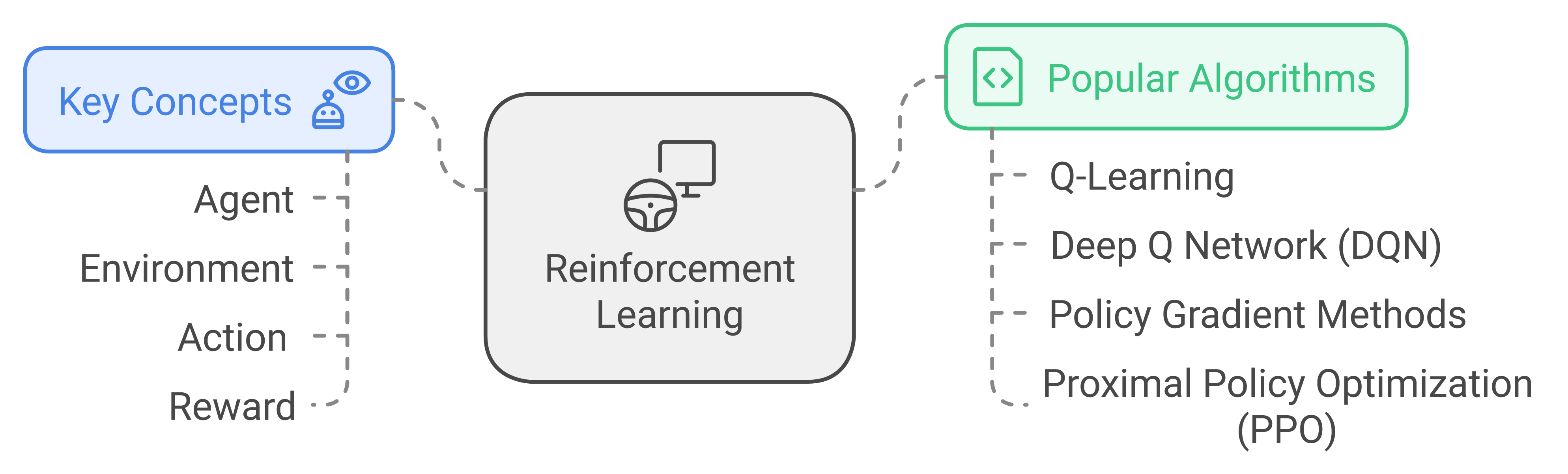
Key concepts:
Agent: The learner or decision-maker
Environment: The world in which the agent operates
Action: A move the agent can make
Reward: Feedback from the environment
Popular Algorithms
Q-Learning: This algorithm learns to make decisions by assigning "quality" values to action-state pairs through trial and error.
Deep Q Network (DQN): A neural network version of Q-learning that can handle complex visual inputs, first mastered by playing Atari games.
Policy Gradient Methods: These algorithms learn by directly adjusting the decision-making policy to maximize expected rewards, rather than learning value functions.
Proximal Policy Optimization (PPO): A simpler and more stable version of policy gradient that limits how much the policy can change in a single update.
Semi-Supervised Learning
This approach combines elements of supervised and unsupervised learning, using a small amount of labeled data along with a larger amount of unlabeled data.
It's particularly useful when obtaining labeled data is expensive or time-consuming.
Transfer Learning
Transfer learning involves applying knowledge gained from one task to a different but related task. This approach can significantly reduce the amount of data and time required to train models for new tasks.
The Machine Learning Process
For successful use of machine learning, it is useful to follow the sequence of steps described below.
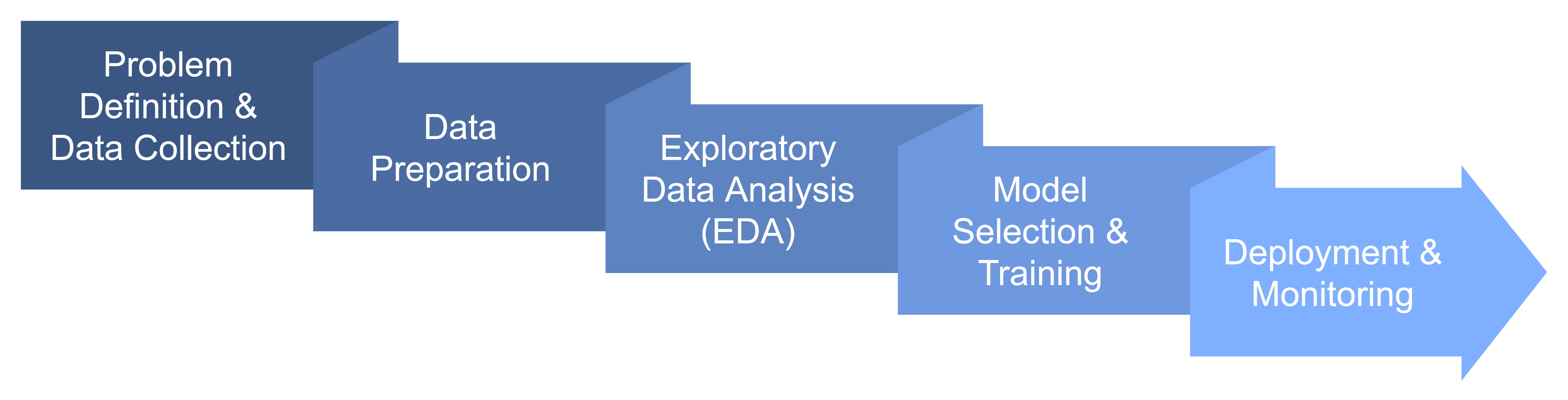
Problem Definition & Data Collection: Clearly define the problem you want to solve and gather relevant data.
Data Preparation: Clean the data (handle missing values, remove duplicates), format it correctly, and perform feature engineering (create or transform features).
Exploratory Data Analysis (EDA): Analyze the data to understand its characteristics and distributions.
Model Selection & Training: Choose an appropriate algorithm, train the model using the prepared data, and evaluate its performance with relevant metrics.
Deployment & Monitoring: Deploy the model into a production environment and continuously monitor its performance, retraining as needed.
Advanced Machine Learning Techniques
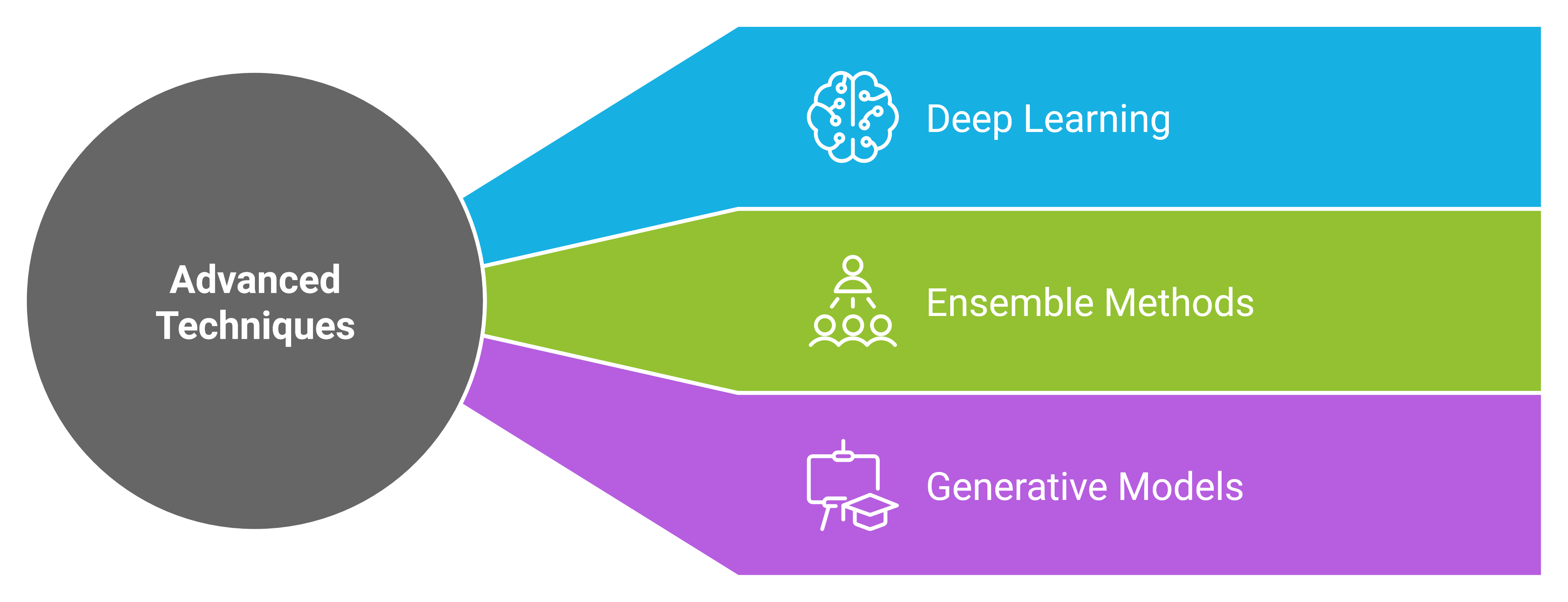
Deep Learning
Deep learning is a subset of machine learning based on artificial neural networks with multiple layers. It has shown remarkable performance in tasks such as image and speech recognition, natural language processing, and game playing.
Key architectures:
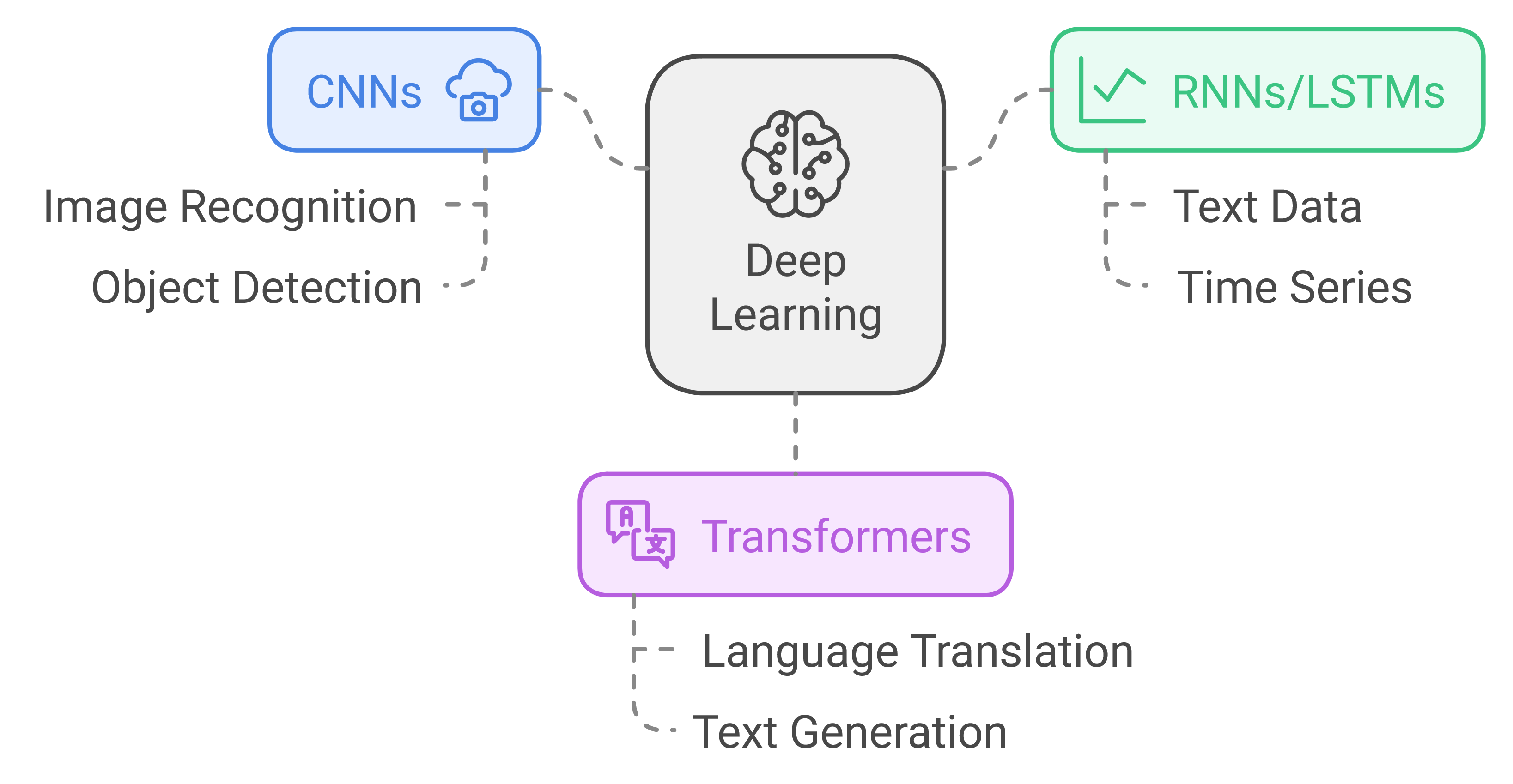
Convolutional Neural Networks (CNNs): Especially effective for image-related tasks
Recurrent Neural Networks (RNNs): and Long Short-Term Memory (LSTM) networks: Suited for sequential data like text or time series
Transformer models: State-of-the-art for many NLP tasks
Ensemble Methods
Ensemble methods combine predictions from multiple models to produce more accurate results. Common techniques include:
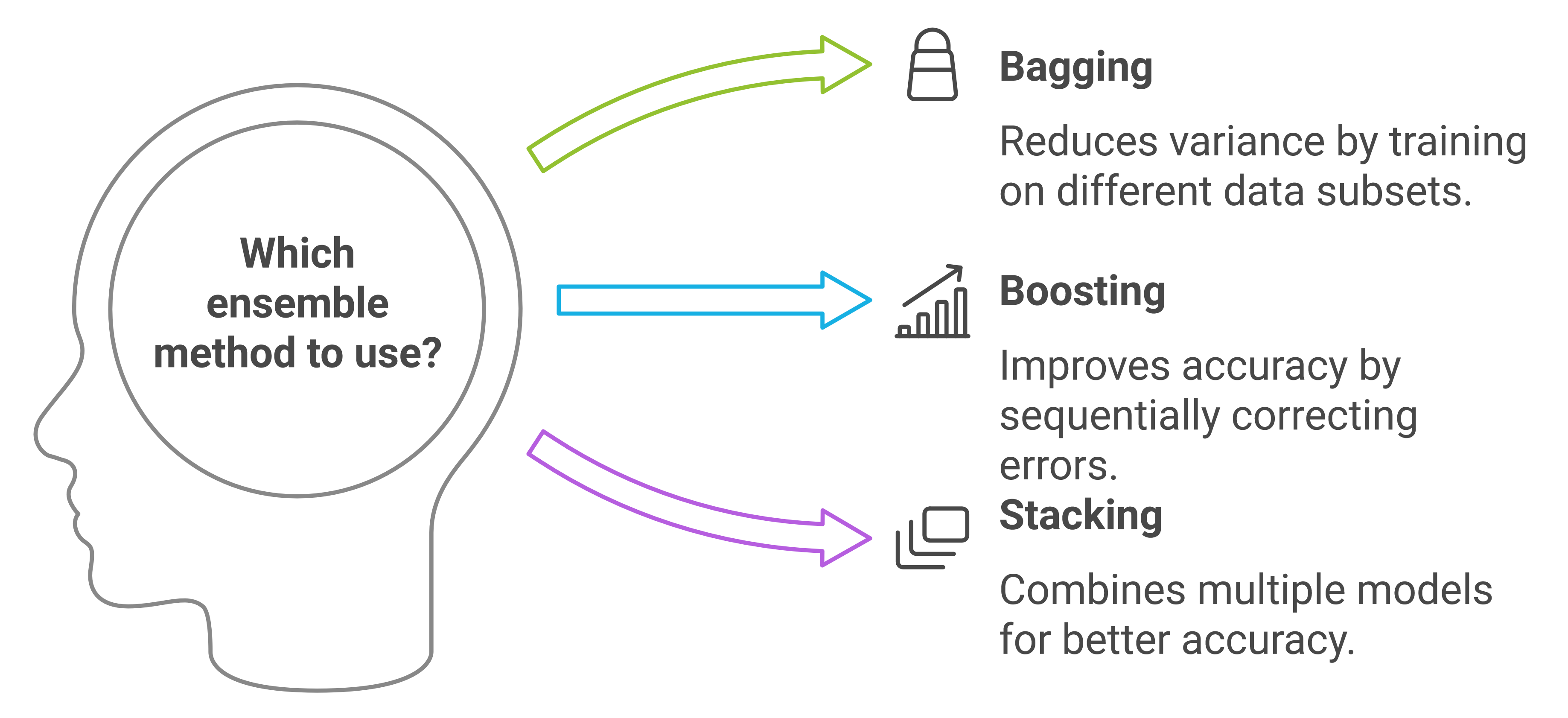
Bagging (e.g., Random Forests): Bagging involves training multiple models on different subsets of the data and combining their predictions to reduce variance and improve overall accuracy.
Boosting (e.g., XGBoost, LightGBM): Boosting is an iterative technique where weak learners are trained sequentially, with each new model correcting the errors of the previous ones to improve prediction accuracy.
Stacking: Stacking combines predictions from multiple models by training a higher-level model to make the final prediction, leveraging the strengths of different algorithms.
Generative Models
Generative models learn to generate new data similar to the training data. Notable examples include:
Generative Adversarial Networks (GANs): Can generate highly realistic images
Variational Autoencoders (VAEs): Used for generating and manipulating complex data distributions
Applications of Machine Learning
Machine learning has found applications across numerous fields:
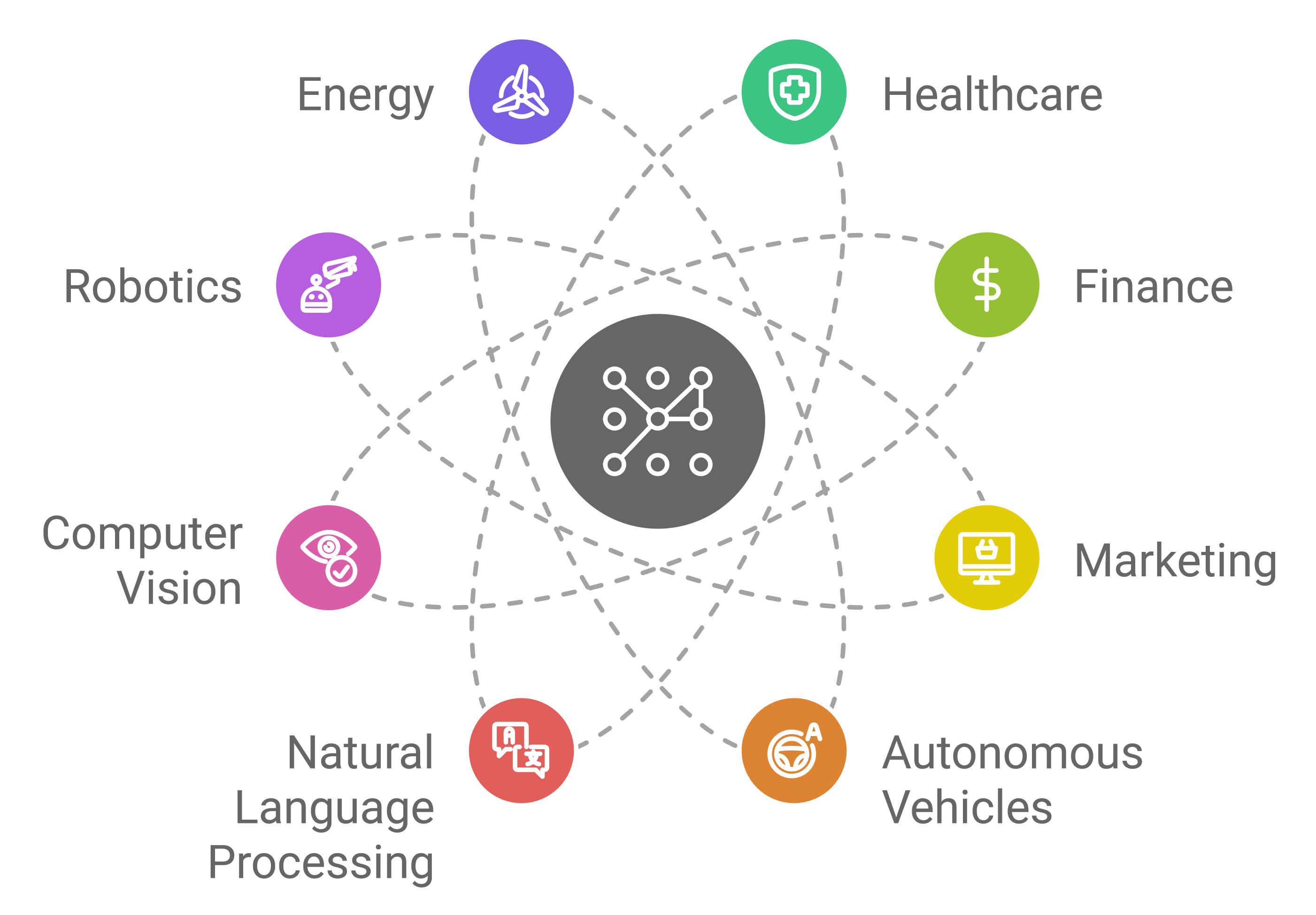
Key industries in particular are benefiting from the use of machine learning:
Healthcare: Machine learning aids in disease diagnosis by analyzing medical data for early signs, which can improve patient outcomes. It also speeds up drug discovery by testing compound effectiveness, and helps design treatment plans tailored to individual health histories.
Finance: ML boosts fraud detection by spotting unusual transaction patterns and helps optimize trades through algorithmic trading. It also powers credit scoring systems, assessing risk to improve lending decisions.
Marketing: Machine learning supports customer segmentation, allowing targeted campaigns for different audiences. It fuels recommendation systems for products or content and predicts customer churn, helping companies retain customers with strategic actions.
Challenges and Considerations
While powerful, machine learning also faces several challenges:
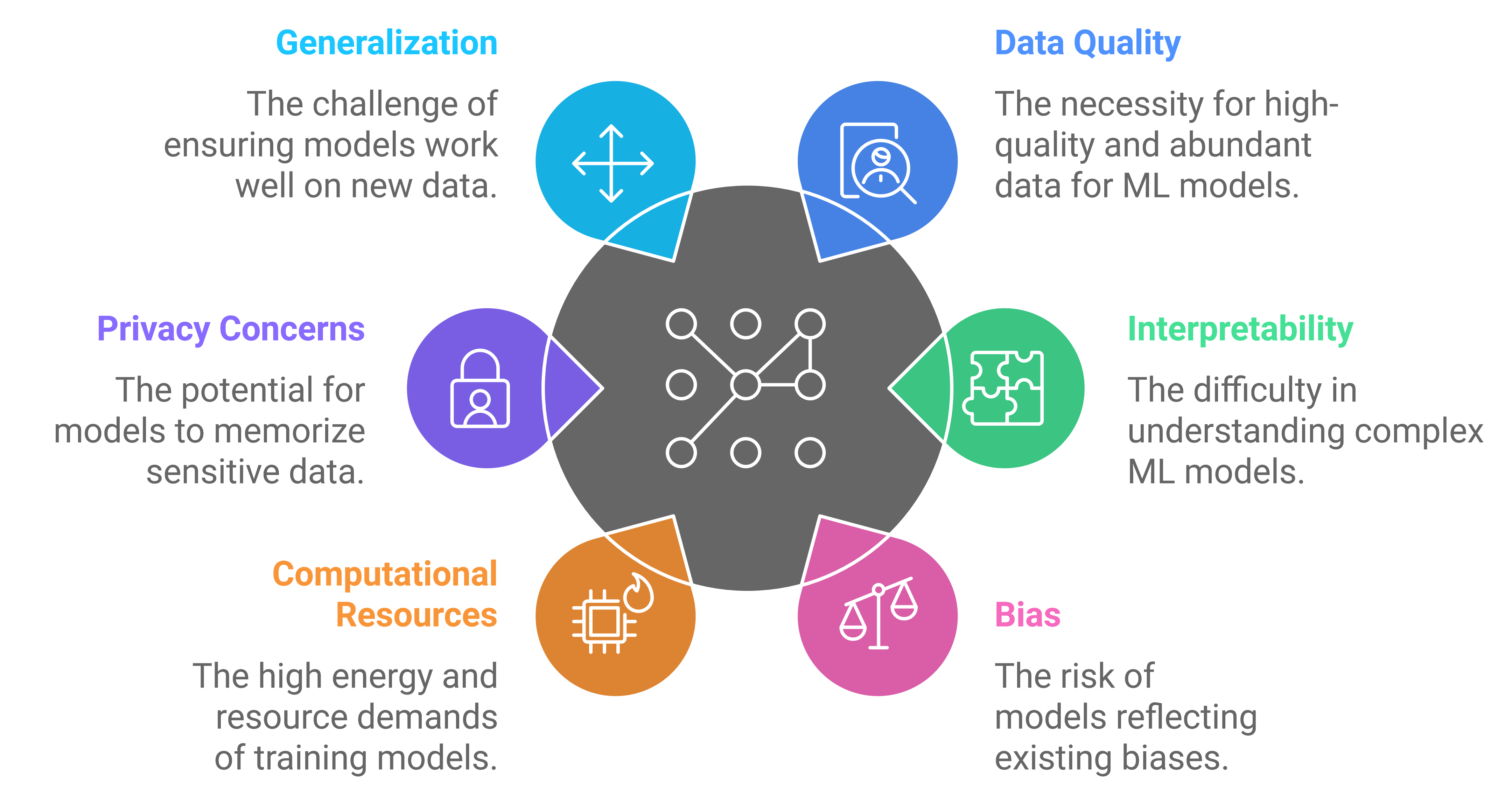
Unreliable Predictions: Inaccurate or incomplete data often leads to biased models, which can create unreliable predictions.
- Example: In healthcare, a model lacking patient data on age or gender may misclassify conditions, resulting in inappropriate treatment recommendations.
Increased Computational and Energy Costs: Increasing Model sizes come with a higher requirement of computational power and energy for training and inference.
- Example: Large Languange models can consume energy comparable to that used by multiple households annually.
Privacy Risks and Compliance Violations: Poorly curated or misclassified data risks exposing sensitive information, posing privacy and compliance issues.
- Example: When GitHub trains its copilot on open repositories, private API keys or sensitive information may inadvertently become part of the dataset. This can lead to unintentional credential leaks.
Future Directions
To address these problems, some areas of ML research are working on solutions.
Explainable AI (XAI) aims to make models more transparent, helping developers understand how predictions are made and detect biases caused by poor data quality. By improving interpretability, XAI not only enhances trust in AI systems but also helps identify and correct data issues before they impact outcomes.
Sustainable AI focuses on reducing the environmental impact of training and deploying models. This includes creating energy-efficient models, leveraging green data centers, and exploring model compression techniques to decrease computational demands.
More exciting areas of development include:
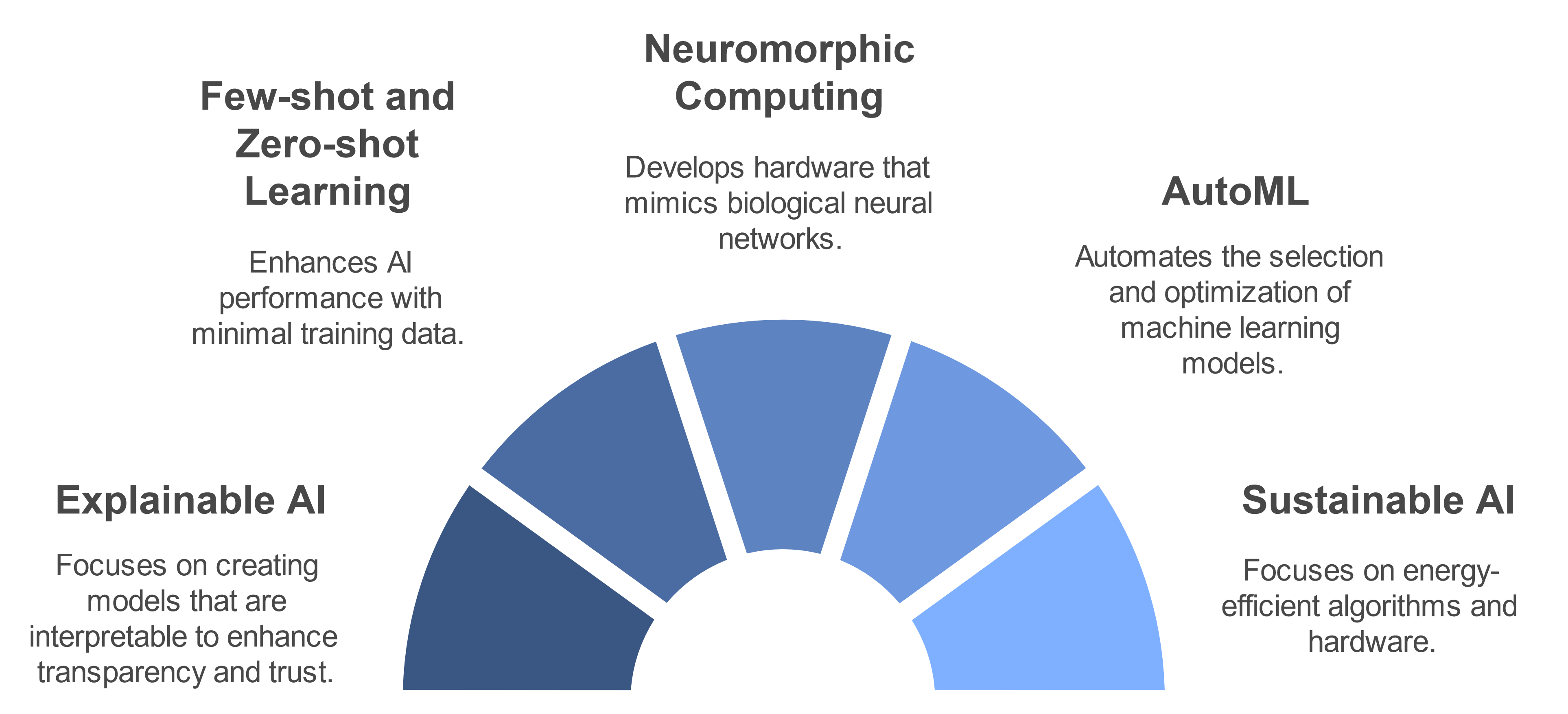
As the field advances, it promises to unlock new possibilities and reshape how we approach complex problems in the future. However, it's crucial to consider the ethical implications and potential societal impacts of these technologies as they become increasingly integrated into our daily lives.
Further Reading
For those interested in diving deeper into machine learning, here are some recommended resources:
Books:
"Pattern Recognition and Machine Learning" by Christopher Bishop
"Deep Learning" by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
"Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow" by Aurélien Géron
Online Courses:
Andrew Ng's Machine Learning course on Coursera
Fast.ai's Practical Deep Learning for Coders
MIT OpenCourseWare's Introduction to Machine Learning
Research Papers:
"A Few Useful Things to Know About Machine Learning" by Pedro Domingos
"Deep Learning in Neural Networks: An Overview" by Jürgen Schmidhuber
Websites and Blogs:
Towards Data Science (https://towardsdatascience.com/)
Machine Learning Mastery (https://machinelearningmastery.com/)
Google AI Blog (https://ai.googleblog.com/)
Remember that the field of machine learning is rapidly evolving, so it's important to stay updated with the latest developments and best practices.




